
作者 | 谢年年
大模型的全参数微调对资源要求非常高,当前业界更倾向于采用LoRA,Parallel Adapter等参数高效微调(PEFT)方法,通过添加只占用LLMs全部参数很小部分(例如,0.1%)的可训练模块,损失小部分精度以换取低资源高效率的微调。
但对于问答(QA)等知识密集型任务来说,当可训练参数受限时,性能下降较为显著。如下图所示,相比全参数微调,其他PEFT方法下降10%左右。
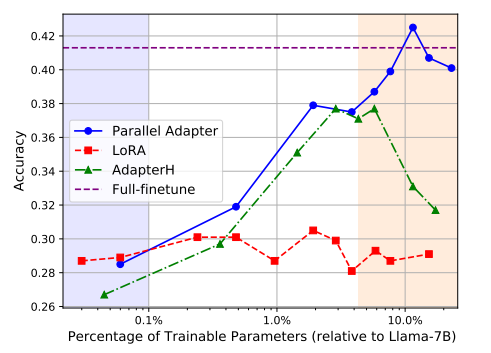
但我们也从中发现,在Parallel Adapter中随着适配器参数数量的增加,答案准确率呈现出明显的上升趋势。大约需要更新10%的参数,可以达到全量微调的性能。但这一方案需要远超24G的GPU内存支持,这在实际应用中仍然面临较高的资源成本。
今天我们介绍一篇来自山东大学的研究,在可训练参数增加的同时显著降低了GPU内存使用,可实现仅需1块3090(24G)训练7B大模型。并且在保持相近性能的同时,相比其他PEFT方法,内存占用率下降了50%。
论文标题:
MEFT: Memory-Efficient Fine-Tuning through Sparse Adapter
前置知识:Parallel Adapter
本文是在Parallel Adapter基础上开展的研究,因此需要先简单了解一下该方法。
在Transformer中,FFN(前馈神经网络)起着关键值记忆的作用,其中每个键对应一种文本模式,每个值则指导输出词汇的分布。基于这一发现,Parallel Adapter通过为下游任务定制特定的知识记忆来扩展原始FFN。Parallel Adapter将adapter与FFN并行放置,adapter由两个线性变换矩阵和以及ReLU非线性激活函数组成。其计算过程可以表述为:
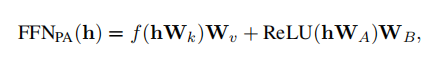
Parallel Adapter中并不是每一个神经元都有作用,即存在稀疏性。作者在Natural Questions数据集上训练了一个瓶颈大小为4096的并行适配器模型。然后在测试集(包含4000个tokens)上提取了适配器的FFNs层的激活,并计算了平均激活值与累积激活值。如下图所示:
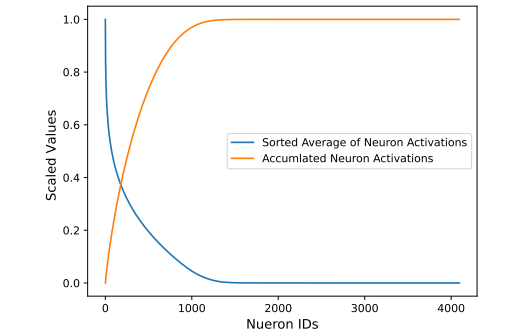
可以看到,适配器中的激活非常稀疏,即只有部分神经元对模型预测有重大贡献,而大部分神经元未被激活。根据这一观察,本文考虑在训练时仅复制这些重要参数,从而减少CPU-GPU通信量和内存使用。
接下来,我们来看看作者是如何激活重要参数的。
方法
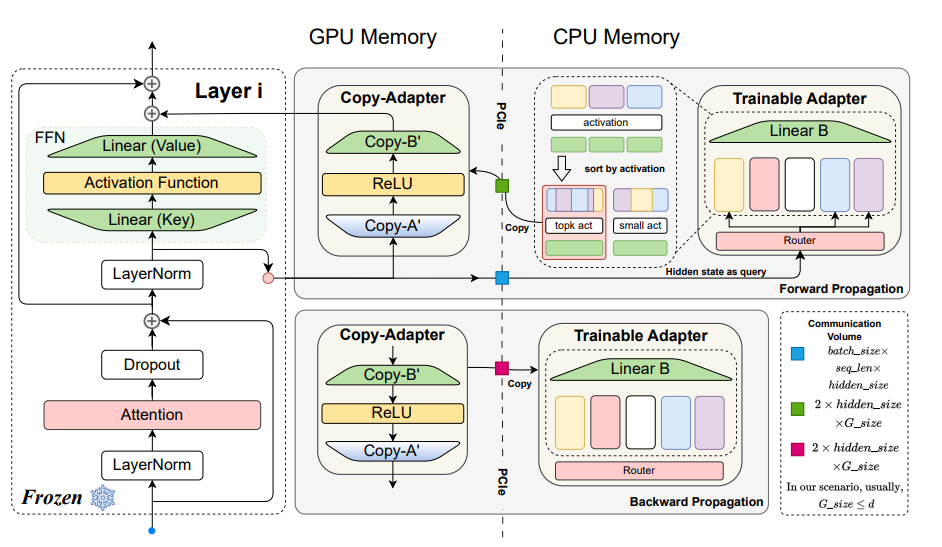
总的来说,本文提出的MEFT方法如上图所示。虚线将参数分成两部分,左侧为GPU,右侧为CPU。大多数可训练的参数将分配给CPU。在前向传播阶段,注意力块的输出将被高效地传递给CPU,使用类似于moe的结构来检索与当前环境高度相关的神经元,将激活神经元将传输到GPU。在反向传播期间,将梯度传输到CPU并更新设置CPU参数。
1. 稀疏激活
FFN块内因ReLU或GELU激活函数存在上下文稀疏性,进一步导致了稀疏梯度。因此本文探索了稀疏Adapter训练,仅更新高激活神经元。在前向计算中,FFN层基于与中个最相似键进行激活:
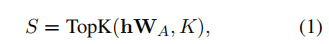
其中, 表示所选键的索引,然后在CPU上使用相关的索引构建和W_B^K
W[·]表示从矩阵W中提取相应值的索引操作。目标是从W_A和W_B中分别提取相关的键和值。接着将W_A^K和W_B^K$ 移动到GPU作为复制适配器,然后作为加宽的FFNs进行计算。
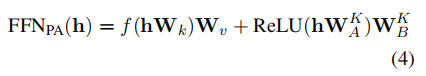
在反向传播中,仅更新激活神经元的梯度,因为未激活神经元不参与FFNPA的计算。通过保留大部分Parallel Adapter参数在CPU内存中,并在每次FFN计算前仅将激活神经元临时复制到GPU内存。由于K远小于总神经元数r,且激活比例通常低于5%,这一策略非常高效,可以显著节省GPU资源。
2. Key-Experts机制
在稀疏激活中,检索最相似权重的TopK操作在CPU上。考虑到当r较大时,给CPU较低的TFLOPs可能成为计算速度的瓶颈。作者进一步提出Key-Experts机制,提高计算效率。
该机制基于MoE的思想,权重和被划分为个专家,并使用一个路由器将输入导向特定的专家。每个专家是一个包含和的FFN。对于输入的token,路由器计算每个专家被选中的分数:
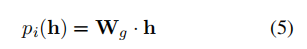
然后选择得分最高的K位专家,将这些选定专家的权重连接到和上:
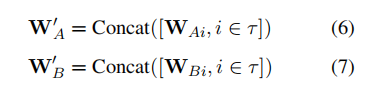
选取前k个键值对,得到,,按照下列算法所示计算FFNPA(h)。

3. 效率分析
虽然该方法通过仅将激活的神经元部分放置在GPU上,可以减少GPU内存使用,但CPU与GPU之间的通信以及CPU计算可能会导致GPU等待。作者分析了该方法的通信量和计算复杂度。
通信量
CPU与GPU之间的参数通信分为前向传播和反向传播两部分。
前向传播。对于每一层,隐藏状态h需要从GPU传输到CPU,这导致了B×l×d的通信开销。在参数选择后,大小为2×d×β×K的激活参数会从CPU传输到GPU。这里,B表示批次大小,l表示批次中序列的长度,β是一个与l相关的稀疏因子。
反向传播。对于每一层,GPU上计算得到的激活参数的梯度被移动到CPU,用于更新CPU端的对应参数。因此,通信量大小等于激活参数的大小,即 2 × d × β ×K。
因此,模型训练的总通信开销为:
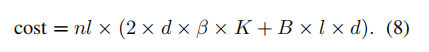
计算复杂度
在CPU上的额外计算包括路由器上的计算和TopK操作。根据提出的Key-Experts机制,CPU上的复杂度为 。因此,当 N 接近时,能达到最优计算复杂度 , 显著降低了计算量,非常适合在CPU上执行。
实证结果
当使用LLaMA-7B作为基础模型,配置为6144的键值对大小、批量大小为2、序列长度为256时,每批的双向通信量约为0.56M次(M代表LLaMA-7B的总可训练参数数)。相比之下,采用deepspeed-offload的Parallel Adapter在相同规模下,每次迭代需要2M的通信量。因此,本文方法在GPU-CPU通信上减少了3.57倍。
在训练效率方面,本文方法相比排除额外通信和CPU计算时间的基线,实证结果显示至少提高了63%的效率。
主要实验结果
下表列出了主要结果。在知识密集型任务(如NQ、SQuAD和Tool)中,MEFT方法在24GB GPU内存限制下显著优于其他PEFT方法。这一提升得益于在有限GPU容量内有效利用了更高的可训练参数比例(即10%)
此外,MEFT在性能上与其他同样包含10%可训练参数的PEFT方法相当,但仅消耗50%的GPU内存,甚至可与全参数模型微调媲美,显著提高了资源利用效率。对于非知识密集型任务如GSM8k,MEFT的稀疏训练策略也展现出不减损性能的稳健性。
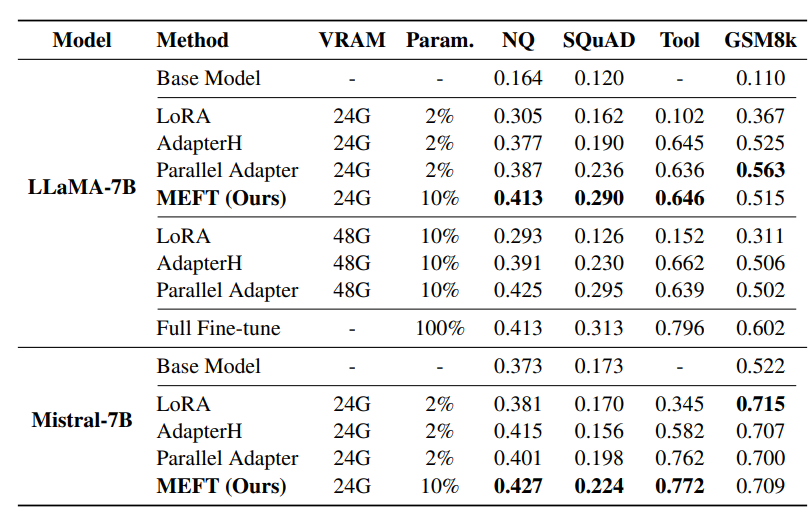
▲VRAM代表训练所需的GPU内存。Param显示模型中可训练参数的百分比。Base Model表示原始模型在任务上的zero-shot性能。稀疏激活机制是否真的有用?
为了减轻CPU的计算负担,本文中使用类似MoE机制。但实验结果表明,这种机制并不是性能提升的主要原因。如下图所示:
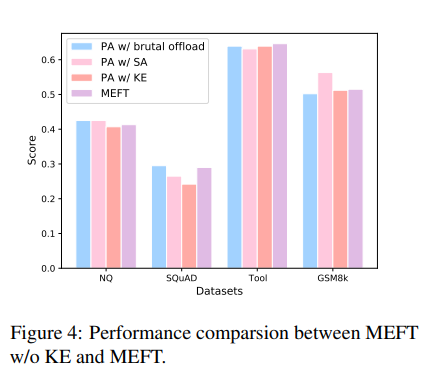
参数对知识密集型任务影响甚微,甚至在SQuAD和ToolBench上提高了性能。brutal offload指的是CPU和GPU之间参数的直接交换。然而,在逻辑成分较强的GSM8k任务上,性能略有下降。这表明逻辑任务可能并不需要大量的参数。
效率分析
下图展示了在RTX 3090 GPU和32核CPU(支持AVX)的服务器上每批次训练的延迟。

图中通过消融研究比较了数据传输、CPU计算和GPU计算的训练时间。其中,“"MEFT w/o both”代表将所有可训练参数移至CPU计算,导致了最高延迟;“MEFT w/o Sparse”移除了稀疏激活,但通过PCIe优化传输必要神经元,降低了数据传输时间,提高了GPU效率;“MEFT w/o KE”采用MoE方法管理参数,减少计算负载但涉及完整参数传输;而“Parallel Adapter”则在GPU上执行所有操作,实现最低延迟。
超参数选择
由于下游任务的性能可能受到众多参数的影响,本文在模型上测试了各种超参数设置。
额外键值对的数量
前文面对知识密集型任务时,通常需要增加额外的参数数量。作者SQuAD和ToolBench数据集上测试了Parallel Adapter的性能,如下表所示,结果显示不同数据集对额外参数的需求存在差异。
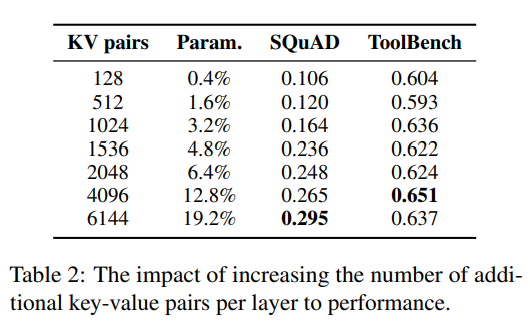
在SQuAD上,随着参数数量的增加,性能稳步提升;然而,在NQ上,每层添加3072个键值对时性能最佳,而ToolBench的最佳性能则出现在每层仅添加1024个键值对时。
激活的键值对数量。
作者研究了限制token可以激活的键值对的数量对模型最终性能的影响。如下图所示:

当选择适当的 K 值时,训练过程中人为添加稀疏约束并未显著影响模型性能。而且,当单个token激活的参数比例低于3%时,显示出合格的性能。
Key-Experts的数量
这里指的是的分区。当每层的Key-Experts数量等于额外的键值对数量时,每个神经元属于独立的专家,相当于不使用MoE分区。
下图所示的结果与这一理论相符:专家数量越多(即分区越多),结果越好。
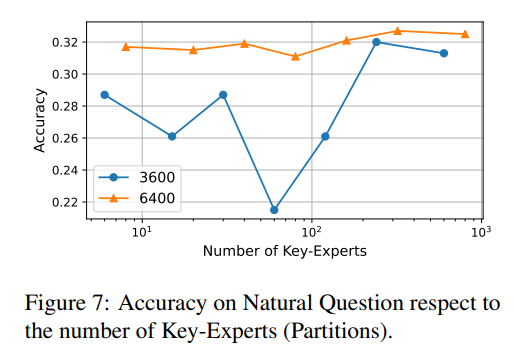
同时,我们发现即使专家数量较少也能获得良好的结果。例如,当专家数量为1时,检索相关神经元的过程可以看作是与路由器的第一次点乘。此时,所有的神经元都处于专家状态E0,在某种程度上相当于有r个分区。
结论
本文发现随着参数的增加,Parallel Adapter可以提升在知识密集型任务上的性能,但伴随着较高资源消耗。为了节约资源,本文提出一种利用稀疏激活和MoE的内存高效训练方法,显著降低了对GPU内存的需求,并减轻其计算压力。这一创新不仅降低了训练成本,也为大模型的高效微调提供了新的可能性。




發表評論 取消回复