
作者|王艺
编辑|赵健
看不下去英伟达的垄断,科技巨头们联合出手了。
据科技媒体TechCrunch最新消息,英特尔、谷歌、微软、Meta、AMD、惠普、博通、思科联合成立了一个新的行业组织——UALink促进会(the Ultra Accelerator Link Promoter Group,超级加速器链接促进会),该组织正在提议制定一项新的行业标准,应用于数据中心里AI芯片之间的互联。
提议标准的第一个版本UALink 1.0将通过单个计算“Pod(舱,服务器中的一个或者多个机架)”连接多达1024个AI芯片(仅限GPU)。据UALink促进会称,UALink 1.0基于包括AMD的Infinity Fabric在内的“开放标准” ,将允许在连接到的AI芯片的内存之间进行直接加载和存储,与现有互连规范相比,可以提高速度并降低数据传输延迟。
同时,该组织表示,将在今年第三季度成立“UALink联盟”,以监督UALink规范未来的发展;UALink 1.0将在同一时间向加入该联盟的公司提供,带宽更高的更新规范UALink 1.1则将于今年第四季度推出。
1.一切都怪英伟达
UALink的名单中,没有英伟达。
这或许和英伟达长期垄断数据中心市场的“霸权”有关——英伟达目前是世界上最大的AI数据中心制造商,约占全球80%-95%的市场份额。凭借着其专有的互联技术NVLink、NVLink Switch(NVSwitch)和Infiniband,英伟达实现了AI芯片和数据中心之间的高速数据传输:
NVLink 是一种专为GPU与CPU之间高速数据传输设计的互连技术,相较于传统的PCIe接口,它提供了更宽的带宽和更低的延迟,极大提升了GPU密集型应用如深度学习、科学模拟和大数据分析的性能;

第五代NVLink极大地提高了大型多GPU系统的可扩展性,单个NVIDIA Blackwell Tensor Core GPU支持多达18个NVLink 100 GB/s连接,总带宽为1.8TB/s,比上一代带宽高2倍,比PCIe Gen5带宽高14倍以上(图源:NVIDIA)
NVSwitch是英伟达开发的一种高速交换机技术,它扩展了NVLink的概念,可以将多个GPU和CPU节点在更大范围内连接起来,形成更为复杂的互连网络。NVSwitch拥有多个NVLink端口,能够在一个系统内实现任意两个GPU之间的直接通信,这对于构建大规模GPU加速的超级计算机和数据中心架构尤为重要;

图源:NVIDIA
NVSwitch可在一台NVL72中实现130TB/s的GPU带宽,以实现大型模型并行; NVL72可以支持的GPU数量是单个八GPU系统的9倍
与此同时,英伟达通过收购Mellanox Technologies,将高速网络解决方案InfiniBand纳入麾下,进一步巩固了其在数据中心生态的影响力。InfiniBand以其极高的数据传输速度和低延迟特性,成为高性能计算集群和数据中心内部通信的优选方案,尤其适合大规模并行计算和存储架构。
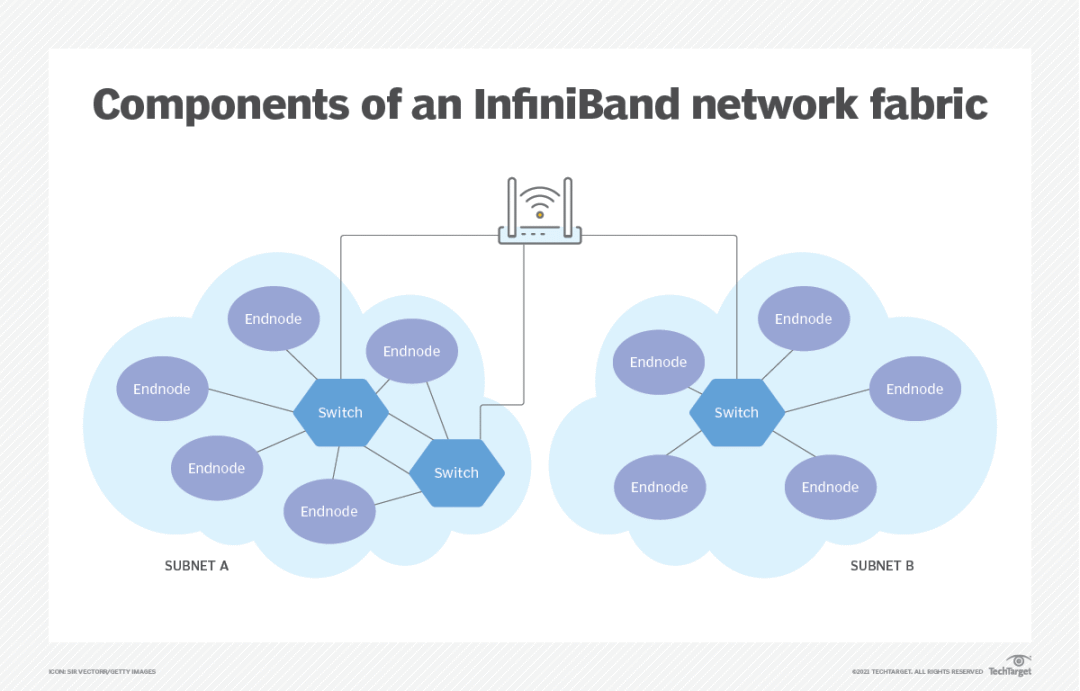
图源:TechTarget
InfiniBand网络由交换机和路由器组成,数据包使用串行方式发送,可以同时发送多个数据通道。
这三者的结合,使得英伟达能够提供端到端的高速数据通路,从GPU到CPU,再到整个网络基础设施,这种垂直整合能力极大地优化了数据处理流程,不仅提升了用户在人工智能、科学模拟、数据分析等领域的计算能力,还极大地增强了英伟达在高性能计算市场的竞争力,确立了其作为行业标准制定者的角色,进一步扩大了其在技术前沿的垄断地位。
英伟达最新财报(2025财年第一财季)显示,英伟达第一季度总营收260亿美元(创历史新高);其中,数据中心业务贡献了英伟达的绝大部分营收,收入达226亿美元,同比增长427%,环比增长23%。如果英伟达继续保持目前增长势头,或许将在今年某个时候超越苹果成为全球第二大市值的公司。
在披露财报的同时,英伟达CFO Colette Kress还表示,“大型云服务提供商大约占据数据中心收入的45%左右”。钱都被英伟达赚了,科技巨头们难免不高兴,因此组团成立UALink定义新的行业标准,试图在英伟达的“垄断”体系下突围。而英伟达不支持基于竞争对手技术的规范也无可厚非。
2.第二次围攻
UALink的成立,是科技巨头们对英伟达的“第二次围攻”。
早在2023年7月,Linux基金会就联合博通、思科等多家公司成立了一个“超级以太网联盟(Ultra Ethernet Consortium)”,通过使用针对AI和HPC工作负载优化的新拥塞控制方法(如晶片堆栈和硅光技术),以实现比InfiniBand或RoCE网络更高效、更具可扩展性的互联网络,从而打破Inifiband的垄断。
而2023年12月,UALink促进会就有了初步的苗头。当时AMD和博通发表了一个联合声明,表示博通未来的PCI-Express交换机将支持xGMI和Infinity Fabric协议,使用NUMA架构,用于AMD的Instinct GPU和CPU之间的相互连接。这一最新交换机被命名为“Atlas 4”,遵循PCI-Express 7.0规范,将于2025年上市。
但PCI-Express不是UALink唯一的互联, xGMI也不是唯一的协议。AMD为UALink贡献了范围更广的Infinity Fabric共享内存协议,而所有其他参与者都同意使用Infinity Fabric作为数据中心互连的标准协议。英特尔高级副总裁兼网络和边缘事业部总经理Sachin Katti表示,UALink促进会正在考虑使用以太网第1层传输层,并在其上采用Infinity Fabric,以便将GPU内存粘合到类似于CPU上的NUMA的巨大共享空间中。
很少有人想过将多个不同供应商的GPU连接到一个机箱内,或者是连接到一个Pod(舱)内。但UALink就在试图这么做——
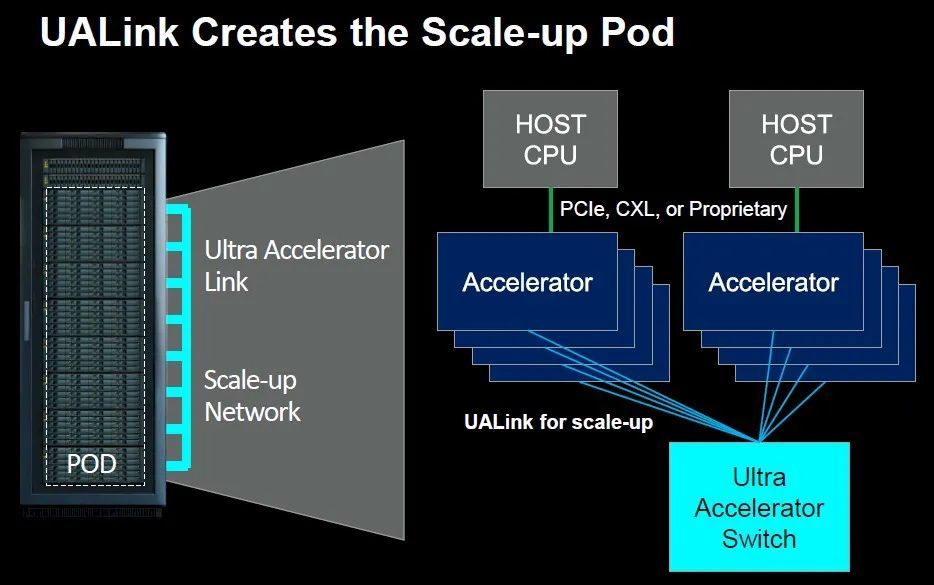
UALink GPU和加速舱(图源:The Next Platform)

使用以太网将Pod链接到更大的集群(图源:The Next Platform)
使用UALink,可以将一个带有AMD GPU的Pod,一个带有Intel GPU的Pod,和另一个带有若干AI芯片的其他品牌供应商的舱连接在一起。就像Meta和微软发布的开放加速器模块 (OAM) 规范允许系统板上加速器插槽的通用性一样,UALink也在互连层面上实现了服务器设计的通用性。
据介绍,Ultra Ethernet仍将用于扩展到更多节点,博通可能会在800Gbps的Thor产品中推出一款早期的Ultra Ethernet NIC,但仅根据规范标准化的程度,可能还需要一代才能获得完整的UEC支持。
对于AMD和英特尔等公司来说,UALink为其提供了一条复制NVLink和NVSwitch、并与其他公司共享开发成果的途径。此外, UALink也让博通这样的公司制造UALink交换机来帮助其他公司扩大规模。
“行业需要一种能够快速推进的开放标准,这种开放标准允许多家公司为整个生态系统增加价值”,在外媒TechCrunch的采访中,AMD数据中心解决方案总经理Forrest Norrod表示,“这种标准需要允许创新不受任何一家公司的束缚,快速推进”。
3.微软、Meta、谷歌或成最大受益者
UALink的最大受益者可能是微软、谷歌以及Meta,它们总计花费了数十亿美元购买英伟达的GPU和服务器来训练其大模型,因此他们迫切地想要摆脱对于英伟达硬件的依赖。
比如谷歌于2020年就在自家的数据中心上部署了当时的最强AI芯片“TPU v4”,去年在Cloud Next 2023大会上推出了新款自研AI芯片TPU v5e,并推出了搭配英伟达(NVIDIA)H100 GPU的 “A3超级计算机”GA(通用版);今年的Cloud Next 2024上,谷歌又宣布推出基于Arm架构的CPU Axion。其性能比通用Arm芯片高30%,比英特尔生产的当前一代x86芯片高50%;
微软于去年11月推出了Azure Maia AI芯片和Azure Cobalt CPU,Maia是为满足微软服务的特定性能要求而定制的,可以显著减少能耗;Cobalt CPU则基于Arm架构构建,以其能效和性能而闻名;此外,微软和OpenAI也计划投入1000亿美元建造超级计算机用于训练大模型,该超级计算机将配备未来版本的Cobalt和Maia芯片,而UALink恰好可以将它们连接起来;
而Meta则在2021年和2022年分别推出了模型训练平台ZionEX和Grand Teton,又在今年在3月宣布设计了两个新的AI计算集群,每个集群包含24576个GPU。这些集群基于Meta的Grand Teton硬件平台,其中一个集群目前被Meta用于训练其下一代Llama 3模型。Meta还致力于PyTorch框架实现,试图用并行化算法,将初始化时间从“有时数小时缩短到数分钟”。
在众多科技巨头的努力下,一个可以与英伟达分庭抗礼的新的互联行业标准,或许离我们不远了。




發表評論 取消回复