IT之傢今日(1月17日)消息,商湯科技與上海 AI 實驗室聯合香港中文大學和復旦大學今日發佈瞭新一代大語言模型書生・浦語 2.0(InternLM2)。

據介紹,InternLM2 是在 2.6 萬億 token 的語料上訓練得到的。沿襲第一代書生・浦語(InternLM)設定,InternLM2 包含 7B 及 20B 兩種參數規格及基座、對話等版本,繼續開源,提供免費商用授權。
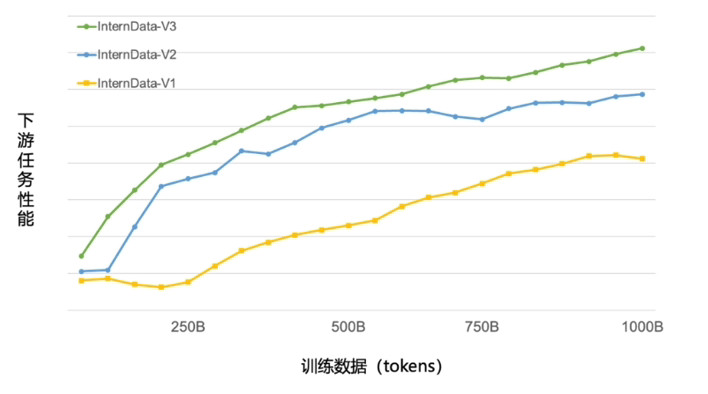
目前,浦語背後的數據清洗過濾技術已經歷三輪迭代升級,號稱僅使用約 60% 的訓練數據即可達到使用第二代數據訓練 1T tokens 的性能表現。
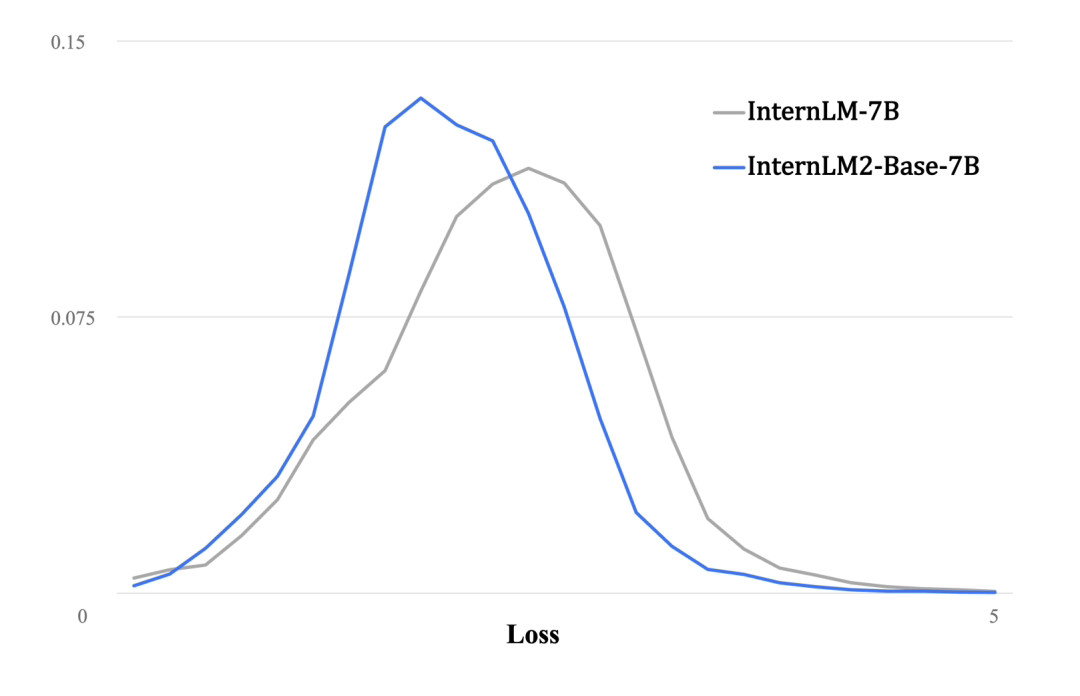
與第一代InternLM相比,InternLM2在大規模高質量的驗證語料上的Loss分佈整體左移,表明其語言建模能力增強。
通過拓展訓練窗口大小和位置編碼改進,InternLM2支持20萬tokens的上下文,能夠一次性接受並處理約30萬漢字(約五六百頁的文檔)的輸入內容。
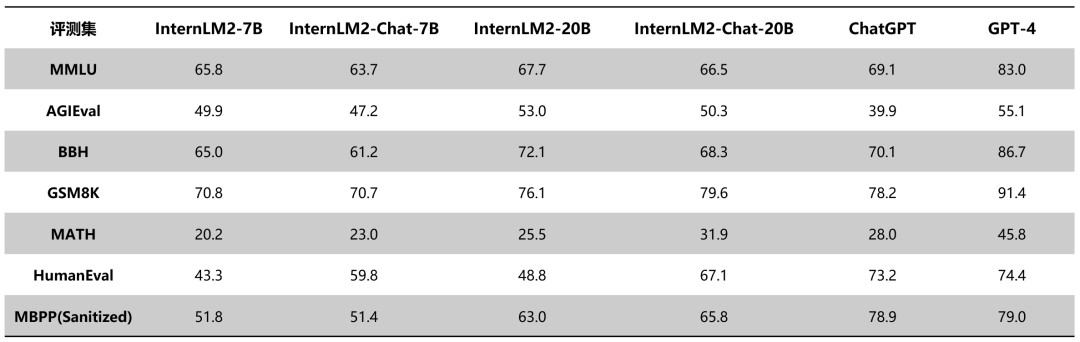
下面表格對比瞭InternLM2各版本與ChatGPT(GPT-3.5)以及GPT-4在典型評測集上的表現。可以看到,InternLM2在20B參數的中等規模上,整體表現接近ChatGPT。


發表評論 取消回复