快科技今日(12月12日)消息,谷歌正式發佈瞭為新智能體時代構建的下一代模型——Gemini 2.0。

這是谷歌迄今為止功能最強的AI模型,帶來瞭更強的性能、更多的多模態表現(如原生圖像和音頻輸出)和新的原生工具應用。
Gemini 2.0關鍵基準測試中相較於前代產品Gemini 1.5 Pro實現瞭性能的大幅提升,速度甚至達到瞭後者的兩倍。
支持圖像、視頻和音頻等多模態輸入與輸出,例如與文本混合的原生文生圖和可自定義的文本轉語音(TTS)多語言音頻內容。
此外還支持原生調用工具,如Google搜索、代碼執行以及第三方用戶定義函數等,為用戶提供瞭更為便捷和強大的功能。
在技術層面,Gemini 2.0采用瞭最新的機器學習和深度學習算法,提升瞭神經網絡的結構和效率,特別是在自然語言處理(NLP)領域表現出色。
這些技術的創新使得Gemini 2.0能夠更好地理解和生成自然語言,增強瞭人機交互的智能性。
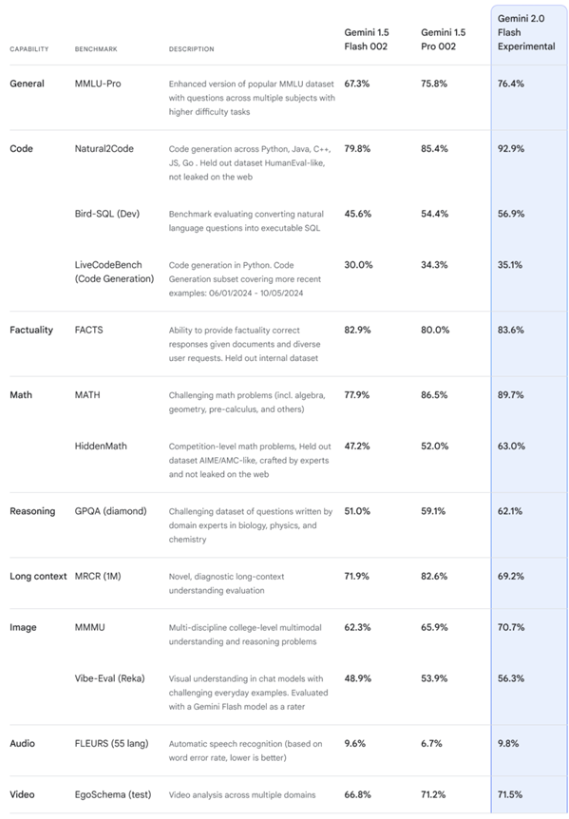
即日起,開發人員便可在AI Studio和Vertex AI中對Gemini 2.0 Flash實驗版本進行試用,而且該版本也已經在網頁版中為Gemini Advanced開放試用,移動版後續也將推出。
為瞭幫助開發者構建動態和交互式應用程序,谷歌還發佈瞭新的Multimodal Live API,具有實時音頻、視頻流輸入以及使用多個組合工具的能力。
明年初,Gemini 2.0還會擴展到更多Google產品中。





發表評論 取消回复