GPT-4V學會自動操縱電腦,這一天終於還是到來瞭。
隻需要給GPT-4V接入鼠標和鍵盤,它就能根據瀏覽器界面上網:

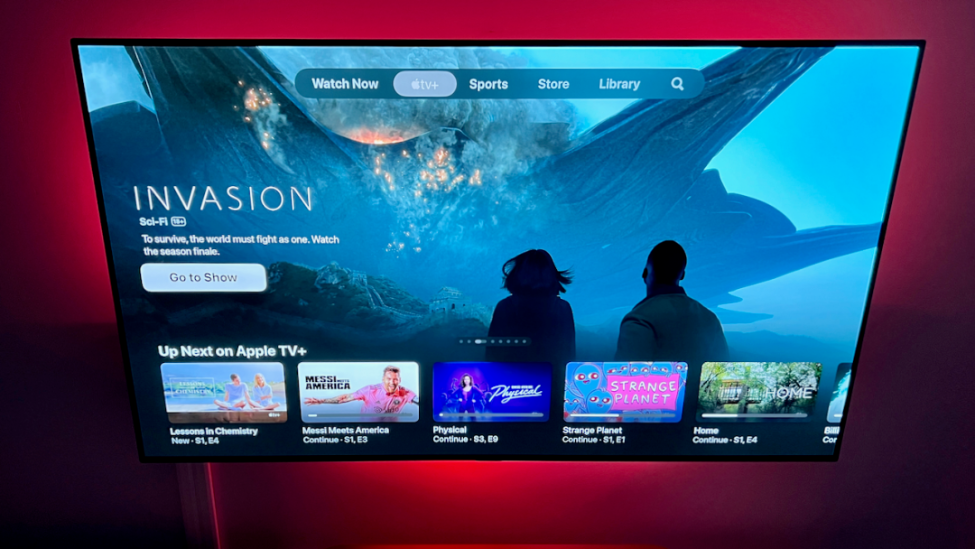
甚至還能快速摸清楚“播放音樂”的播放器網站和按鈕,給自己來一段music:

是不是有點細思極恐瞭?
這是一個MIT本科生小哥整出來的新活,名叫GPT-4V-Act。

隻需要幾個簡單的工具,GPT-4V就能學會控制你的鍵盤和鼠標,用瀏覽器上網發帖、買東西甚至是玩遊戲。
要是用到的工具出bug瞭,GPT-4V甚至還能意識到、並試圖解決它。

來看看這是怎麼做到的。
教GPT-4V“自動上網”
GPT-4V-Act,本質上是一個基於Web瀏覽器的AI多模態助手(Chromium Copilot)。
它可以像人類一樣用鼠標、鍵盤和屏幕“查看”網頁界面,並通過網頁中的交互按鍵進行下一步操作。
要實現這種效果,除瞭GPT-4V以外,還用到瞭三個工具。
一個是UI界面,可以讓GPT-4V“看見”網頁截圖,也能讓用戶與GPT-4V發生交互。
這樣,GPT-4V就能將每一步運行思路都通過對話框的形式反映出來,用戶來決定是否要繼續讓它操作。

另一個是Set-of-Mark Prompting(SoM)工具,讓GPT-4V學會交互的一款工具。

這個工具由微軟發明,目的是更好地對GPT-4V進行提示詞工程。
相比讓GPT-4V直接“看圖說話”,這個工具可以將圖片關鍵細節拆分成不同的部分,並進行編號,讓GPT-4V有的放矢:

對於網頁端也是如此,Set-of-Mark Prompting用類似的方式讓GPT-4V知道從網頁瀏覽器的哪個部分找答案,並進行交互。
最後,還需要用到一個自動標註器(JS DOM auto-labeler),可以將網頁端所有能交互的按鍵標註出來,讓GPT-4V決定要按哪個。

一套流程下來, GPT-4V不僅能準確判斷圖片上的哪些內容符合需求,還能準確找到交互按鍵,並學會“自動上網”。
這是個大項目,目前還隻實現瞭部分功能,包括點擊、打字交互、自動標註等。
接下來,還有其他的一些功能要實現,例如試試AI打標器(目前網頁端的交互還是通過通過JS接口得知哪裡能交互,不是AI識別的)、以及提示用戶輸入詳細信息等。

此外,作者也提到,現階段GPT-4V-Act用法上還有一些需要註意的地方。
例如,GPT-4V-Act可能會被網頁打開後鋪天蓋地的彈窗小廣告給“整懵瞭”,然後出現交互bug。

又例如,目前這種玩法可能會違反OpenAI的產品使用規定:
除非API允許,否則不得使用任何自動化或編程的方法從服務中提取數據並輸出,包括抓取、網絡收集或網絡數據提取。

所以用的時候也要低調一點(doge)
微軟SoM作者也來圍觀
這個項目在網上發出後,吸引瞭不少人的圍觀。
像是小哥用到的微軟Set-of-Mark Prompting工具的作者,就發現瞭這個項目:
出色的工作!
![]()
還有網友提到,甚至可以用來讓AI自己讀取驗證碼。

這個在SoM項目中提到過,GPT-4V是能成功解讀驗證碼的(所以以後可能還真不知道是人還是機器在上網)。

與此同時,也有網友已經在想象桌面流自動化(desktop automation)的操作瞭。
對此作者回應稱:
AI自動標註器應該能實現這個,我也確實在計劃制作一個更通用的Copilot。

不過目前GPT-4V還是要收費的,有沒有其他的實現方法?
作者也表示,目前還沒有,但確實可能會嘗試Fuyu-8B或者LLaVAR這樣的開源模型。

免費的自動化桌面流AI助手,可以期待一波瞭。
責任編輯:隨心




發表評論 取消回复