在五月底的Computex上,Nvidia發佈瞭新一代超算DGX GH200。根據Nvidia的官方資料,該DGX GH200超級計算機將基於其Grace Hopper superchip,在DGX GH200中,可包含多達256個Grace Hopper超級芯片,能提供高達1 EFLOPS的AI算力,另外每個DGX GH200中,都能提供高達144TB的內存,GPU和CPU之間的帶寬則達到瞭900 GB/s。在數據互聯方面,DGX GH200使用瞭NVLink,並且使用瞭自研的NVSwitch網絡交換芯片來滿足互聯的性能和可擴展性。

我們可以看到,DGX GH200中,最關鍵的芯片,包括CPU/GPU以及數據互聯等,幾乎都是Nvidia自研的芯片。相比而言,上一代使用Hopper GPU的超算DGX H100 SuperPOD還是在使用Intel的Sapphire Rapids CPU,並且由於Intel的CPU並不提供NVLink的接口,因此限制瞭其內存空間的可擴展性——上一代DGX H100 SuperPOD的內存是20TB,而DGX GH200則提供瞭144TB,直接翻瞭7倍以上。我們將會在接下來的分析中看到,內存空間的拓展是目前超級計算機最關鍵的指標之一,而Nvidia在多年芯片架構方面的努力之後,終於有機會能使用自研芯片來實現這樣一個內存空間大到驚人的超級計算機。
DGX GH200超級計算機主要針對超高性能人工智能計算。根據目前Nvidia的消息,谷歌和微軟等人工智能領域的領軍企業將會成為DGX GH200的首批客戶。
大模型人工智能時代,超級計算機重要性凸顯
目前,人工智能已經進入瞭以大模型為主導的下一個時代。以ChatGPT為代表的大語言模型可以從海量的語料數據中學習並且擁有前所未有的能力,但是相應地這些大語言模型也有相當大的參數量,例如根據現有的資料,OpenAI的GPT4有大約1T的參數量。除瞭在自然語言處理方面之外,大模型人工智能模型也廣泛應用在推薦系統等領域。隨著這些大模型的進一步發展,預計大模型參數量很快就會進入到1T乃至10T數量級。
顯然,這樣的模型不可能在單臺常規服務器上進行訓練,因為單臺服務器的內存不足以支撐這些大模型的訓練/推理任務。因此,在人工智能領域,通用的做法是把這些大模型分散(sharding)在多臺服務器上進行訓練和推理。
舉例來說,可以把一個大模型分散到32臺服務器上進行訓練,其中每臺服務器都有自己獨立的內存空間,並且負責大模型神經網絡中一些層的執行(以確保每臺服務器的內存足夠容納相應的計算任務),然後每臺服務器在完成計算之後,通過網絡把結果歸並到一起成為最終的結果。
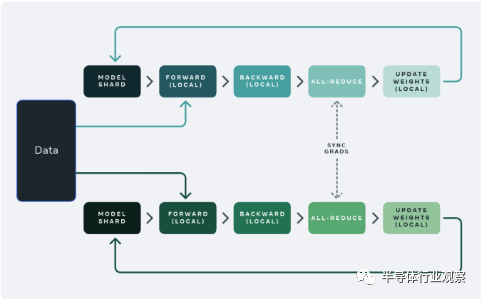
這樣常規的分佈式計算的做法理論上可以支持無限大的模型,隻要能夠把模型劃分到足夠細的顆粒度讓單臺服務器可以容納即可。然而,這樣的做法有一個明顯的系統瓶頸,就是在這樣的雲端分佈式計算中,每臺服務器之間通常使用網絡(以太網或者更高速的InfiniBand)連接在一起,因此每次計算的結果歸並部分往往就會成為系統性能瓶頸,因為在歸並這一步需要把每臺服務器的數據通過網絡傳遞到一起,而顯然在分佈式計算中服務器數量越多且網絡帶寬越小/延遲越大,整體的性能就會越差。
在這樣的背景下,超級計算機有機會會成為大模型時代的重要計算范式。和分佈式計算略有不同的是,超級計算機強調把高性能計算單元盡可能集中,並且使用短距離超高帶寬/超低延遲的數據互聯連接在一起。由於這些計算單元之間的數據互聯性能遠高於使用長距離的以太網/InfiniBand,因此整體性能並不會受到數據互聯帶寬的太多限制。相比傳統的分佈式計算,使用超級計算機的方式可以在峰值算力相同的情況下,實現更高的實際計算能力。
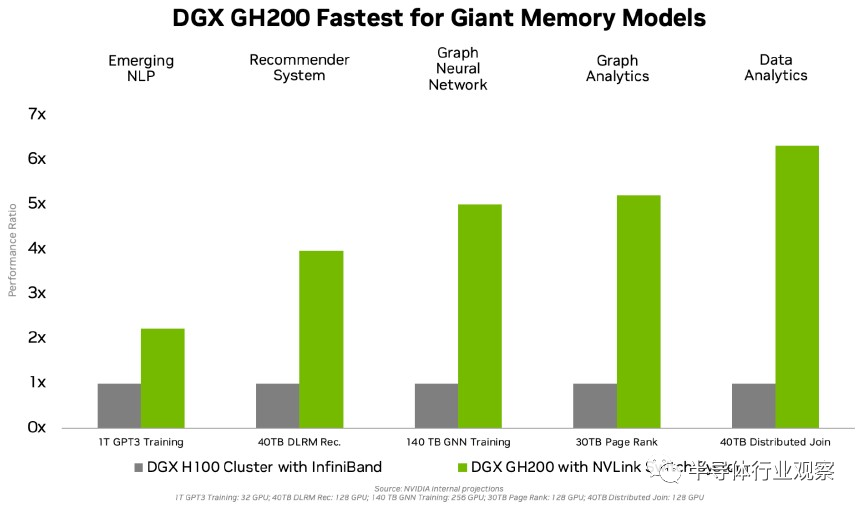
在上一代人工智能計算(以計算機視覺領域的ResNet-50為代表)的范式中,每個模型的參數量大約在100M左右,每臺服務器容納下模型並不存在任何問題,因此在訓練過程中通常不涉及到模型sharding的問題,數據互聯也不是整體性能的瓶頸,從而超級計算機並沒有得到那麼多的關註。而在大模型時代,由於模型尺寸已經超過瞭每臺服務器能夠容納的極限,因此如果需要實現高性能訓練和推理,像DGX GH200這樣的超級計算機就成為瞭非常好的選擇。而且,隨著模型參數量越來越大,對於超級計算機的內存容量也提出瞭越來越多的要求。Nvidia這次也發佈瞭DGX GH200和上一代DGX H100性能的比較,我們可以看到在GPU數量相同的情況下,對於大模型應用,擁有更多內存且使用NVLink的DGX GH200的性能要數倍於內存較小且使用InfiniBand的DGX H100。
Grace-Hopper架構解析
在DGX GH200中,使用的是Grace Hopper superchip,每個DGX GH200中可以搭載多達256個Grace Hopper superchip。

什麼是Grace Hopper superchip?根據Nvidia發佈的白皮書,Hopper是Nvidia最新基於Hopper架構的GPU(即H100系列),而Grace則是Nvidia自研的基於ARM架構的高性能CPU。從指標上來說,Grace Hopper superchip可以包含至多72個CPU核,而CPU通過LPDDR5X接口接瞭高達512GB的內存,內存帶寬達546 GB/s。而GPU這邊則通過HBM3接口接瞭最多96GB的顯存,帶寬可達3TB/s。除瞭CPU和GPU之外,Grace Hopper superchip中另一個至關重要的組件是NVLINK Chip-2-Chip(C2C)高性能互聯接口。在Grace Hopper superchip中,Grace CPU和Hopper GPU通過NVLINK C2C連接起來,該互聯可以提供高達900GB/s的數據互聯帶寬(相當於x16 PCIe Gen5的7倍)。此外,由於NVLINK C2C可以提供一致性內存接口,因此GPU和CPU之間的數據交換變得更加高效,GPU和CPU可以共享同一個內存空間,系統應用可以隻把GPU需要的數據從CPU的內存搬運到GPU,而無需把整塊數據都復制過去。
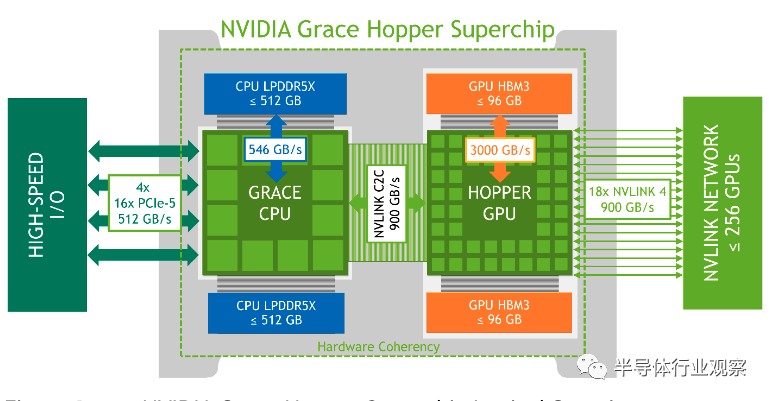
從物理上說,Grace Hopper的CPU和GPU芯片仍然是兩塊獨立的芯片,並且互聯使用的也是PCB板上的走線;但是從邏輯上說,由於CPU和GPU都可以看到同一個內存空間,因此可以看作是一個整體。
Grace Hopper superchip在設計的時候,可擴展性顯然是作為首要指標在考慮。在這裡,NVLink再次發揮瞭至關重要的左右:每個Grace Hopper superchip可以使用NVLink Switch以900GB/s的超高帶寬與其他Grace Hopper superchip互聯在一起,這樣的互聯最多可以支持256個Grace Hopper superchip形成一個superchip pod——而這也是Nvidia在這次發佈的DGX GH200中的互聯方式。除此之外Grace Hopper superchip還可以通過與Nvidia Bluefield DPU的接口去連接InfiniBand,這樣superchip pod之間可以通過InfiniBand的辦法進一步擴展到更大的規模,從而實現更高性能的計算。
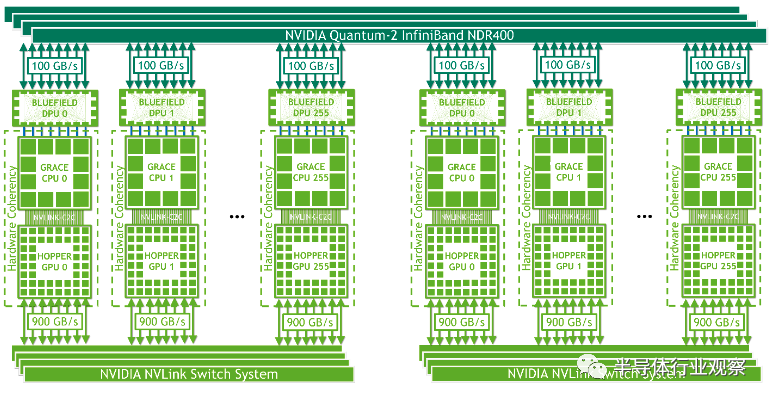
通過上述分析,我們看到在Grace Hopper superchip中,Nvidia的NVLink系列超高性能數據互聯起到瞭至關重要的作用,通過提供高達900GB/s的帶寬並且提供一致性接口,Grace Hopper superchip實現瞭非常強的可擴展性。Grace Hopper superchip中CPU與其他高性能服務器端ARM CPU的區別可能就是對於NVLink接口的支持,而這也成瞭Grace Hopper superchip最大的亮點。
未來競爭格局前瞻
Nvidia通過發佈擁有驚人性能和內存容量的DGX GH200超級計算機來宣示其Grace Hopper superchip對於下一代大模型人工智能的領先加速能力,與此同時我們也看到類似Grace Hopper superchip這樣的通過緊密耦合CPU和GPU(以及其他加速器),並且通過搭載超高速一致性內存接口來實現對於大模型的高效支持,將會成為未來人工智能芯片領域的重要設計范式。
目前來看,在下一代大模型支持領域,Nvidia無疑是芯片行業最領先的選手,而有實力在未來和Nvidia一爭高下的廠商有可能是AMD。事實上,AMD和Nvidia在這個領域的設計思路非常接近。Nvidia有Grace Hopper superchip,而AMD的相關產品則是CDNA3 APU。在CDNA3 APU架構中,AMD把CPU和GPU通過芯片粒的方式集成在一起,並且使用一致性數據互聯來支持統一的內存空間。在AMD最新發佈的MI300產品中,每個APU集成瞭24個Zen 4 CPU核以及若幹個使用CDNA3架構的GPU(具體數據有待發佈),並且搭載瞭128 GB HBM3內存。
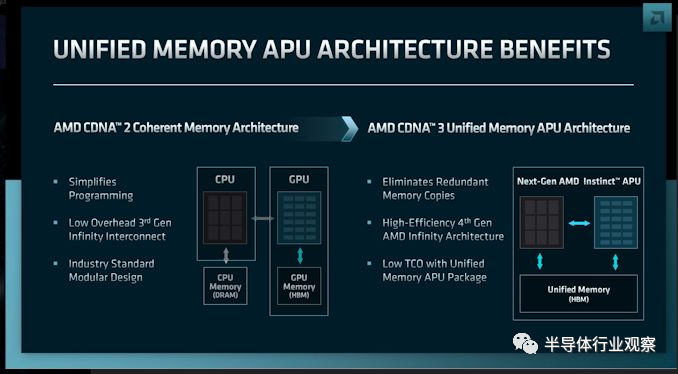
如果我們比較Nvidia和AMD的設計,我們可以看到把CPU和GPU做緊密耦合並且使用一致內存空間的思路完全一致,但是具體設計中也有幾個關鍵的不同:
首先,AMD使用的是高級封裝芯片粒的技術來實現CPU和GPU的集成,而Nvidia則是基於其在NVLink技術上的自信使用傳統的PCB來集成CPU和GPU。但是,這一點在未來可能會發生改變;隨著PCB的數據互聯帶寬越來越接近極限,預計Nvidia也會在未來越來越多使用高級封裝技術來完成互聯。
其次,Nvidia在內存空間和可擴展性領域更加激進。每個Grace Hopper superchip的內存可達600GB,而通過NVLink Switch更是可以實現高達144TB的內存空間;而相比之下AMD的CDNA3 APU的內存空間僅為128 GB。這裡,我們看到Nvidia多年來在一致性數據互聯領域的技術投入顯然起到瞭非常好的效果,在未來大模型領域這類超高可擴展性數據互聯用於擴展內存空間可望成為關鍵的技術,而在這一點上AMD也需要繼續投入來追趕Nvidia的領先地位。




發表評論 取消回复