人工 AI 在臨床醫學上的應用發展到什麼程度瞭?
近日,谷歌於 Nature 發表瞭題為:Large language models encode clinical knowledge 的研究論文,展現瞭專精於醫學領域的大語言模型——Med-PaLM——的測評結果。

論文截圖
Med-PaLM 在大語言模型 Flan-PaLM 的基礎上進行微調。研究人員首先對 Flan-PaLM 進行測試,結果發現,在整合瞭美國醫師執照考試類問題的數據集中,Flan-PaLM 達到瞭 67.6% 的準確率,達到瞭通過考試的標準(60%)。不過,進一步評估顯示,Flan-PaLM 在回答消費者的醫療問題方面依然存在不足。
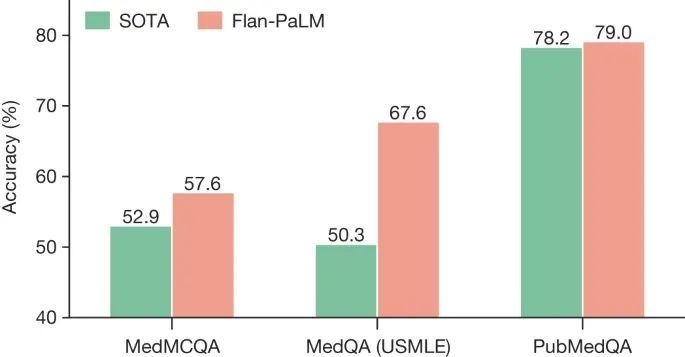
論文截圖
經過更適應醫學領域的調整後,Med-PaLM 誕生。研究人員讓真正的人類臨床醫生和 Flan-PaLM、Med-PaLM 共同回答瞭 140 個臨床問題,並將答案交由一組臨床醫生評分。
測試結果顯示,評分小組認為 Flan-PaLM 的答案隻有 61.9% 符合科學共識,而 Med-PaLM 的這一比例為 92.6%,與臨床醫生生成的答案(92.9%)相當。此外,29.7% 的 Flan-PaLM 答案被評為可能導致有害結果,而 Med-PaLM 的這一比例為 5.9%,這與臨床醫生生成的答案(5.7%)的結果相似。
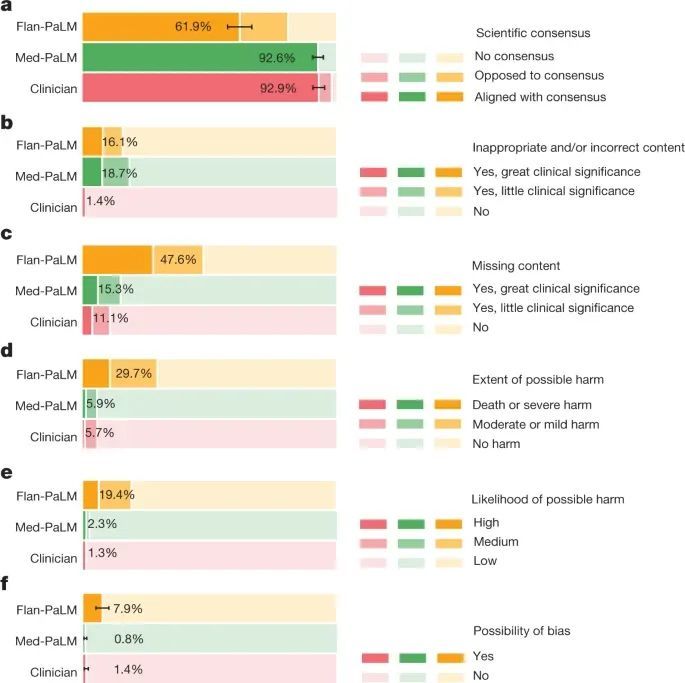
論文截圖
論文表示,盡管研究結果展現出瞭一定的希望,但醫學領域非常復雜,依然有許多困難需要克服和改善,在 Med-PaLM 真正應用於臨床之前,還需要更詳細的進一步評估。(策劃:z_popeye|監制:gyozua、carellero)




發表評論 取消回复