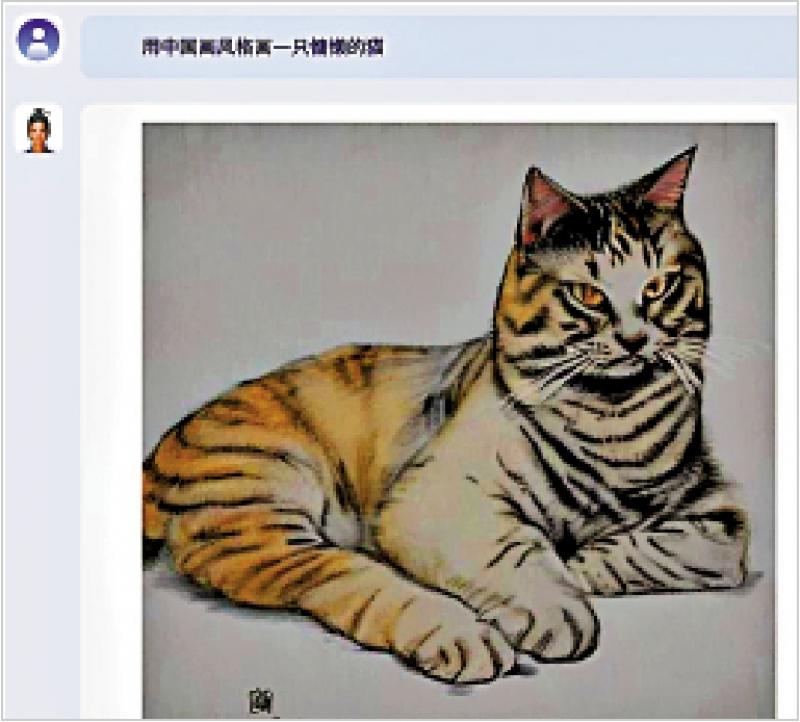
圖:“紫東太初”能夠讀懂文字、圖像,並應詢繪畫畫作。\網絡圖片
【大公報訊】記者劉凝哲北京報道:中國科學院自動化研究所所長徐波16日在人工智能框架生態峰會2023上正式發佈“紫東太初”全模態人工智能大模型。作為升級後的2.0版本,“紫東太初”不光能讀懂文字、圖像,還能理解音頻、視頻,甚至3D模型、傳感信號,思考起來更像“真人”。值得一提的是,“紫東太初”不僅實現能力提升,還做到全鏈條“中國造”,打造出全棧國產化的通用人工智能底座。
2021年7月,全球首個千億參數的多模態大模型“紫東太初”1.0就已發佈,實現圖像、文本、語音三類數據的相互生成。歷經近2年的迭代,“紫東太初”2.0除瞭讀懂圖文外,還能看懂來自現實世界的影像數據、力觸覺、工業傳感信號等物聯數據,可以像人一樣綜合運用多種信號進行思考。
在人工智能框架生態峰會上,徐波首次對外實時展示瞭大模型在音樂理解與生成、三維場景導航、信號理解、多模態對話等方面的全新功能,並邀請現場觀眾與大模型即時互動。“紫東太初”全模態認知大模型不僅可以透過《月光曲》暢談貝多芬的故事,也可以在三維場景裡實現精準定位,還能夠通過圖像與聲音的結合完成場景分析,現場反響熱烈。
參與突破罕見病診療難題
據介紹,“紫東太初”大模型目前已展現出廣闊的產業應用前景,在神經外科手術導航、短視頻內容審核、法律咨詢、醫療多模態鑒別診斷、交通違規圖像研讀等領域開始瞭一系列引領性、示范性應用。在醫療場景,“紫東太初”可實現在術中實時融合視覺、觸覺等多模態信息,協助醫生對手術場景進行實時推理判斷。此外,科研團隊還與北京協和醫院合作,利用“紫東太初”具備的較強邏輯推理能力,嘗試在人類罕見病診療這個挑戰性醫學領域有所突破。
徐波表示,將“紫東太初”大模型為基礎,持續探索與類腦智能、博弈智能等技術路徑的相互融合,最終實現可自主進化的通用人工智能。




發表評論 取消回复